Gensparkでスライド作成、リサーチ込み1本70円。PPTX書き出しなら仕事で使える!
大下勇次
クリメモ クリエイティブ備忘録


この記事は、前回の記事とセットになってます。
前回は人間の私が理解している内容に基づき、AIの支援を受けて書きました。
今回は逆で、私が正直よくわかっていない技術的な仕組みについて、Claudeに解説してもらった内容をもとに、AIに記事として整理してもらったものになります。
具体的には、開発担当のClaude codeにお願いして、ブログ記事にする前提でこれまでの開発経過ドキュメントを元に全体の流れをマークダウンファイルに出力してもらい、それをブログ記事化担当AIに渡して書いてもらった記事になります。最低限人間チェックはしてますが、、、。
人間が理解している内容に基づく別切り口の記事はこちら↓

なので今回の記事は、前回よりもう少し技術オタク寄りの内容。AIプレゼン自動生成に興味があるエンジニアや、Claude Codeで何かツールを作ってみたい人向け。
さらに、私も細かい技術的な内容は理解していないというおもしろ記事です。
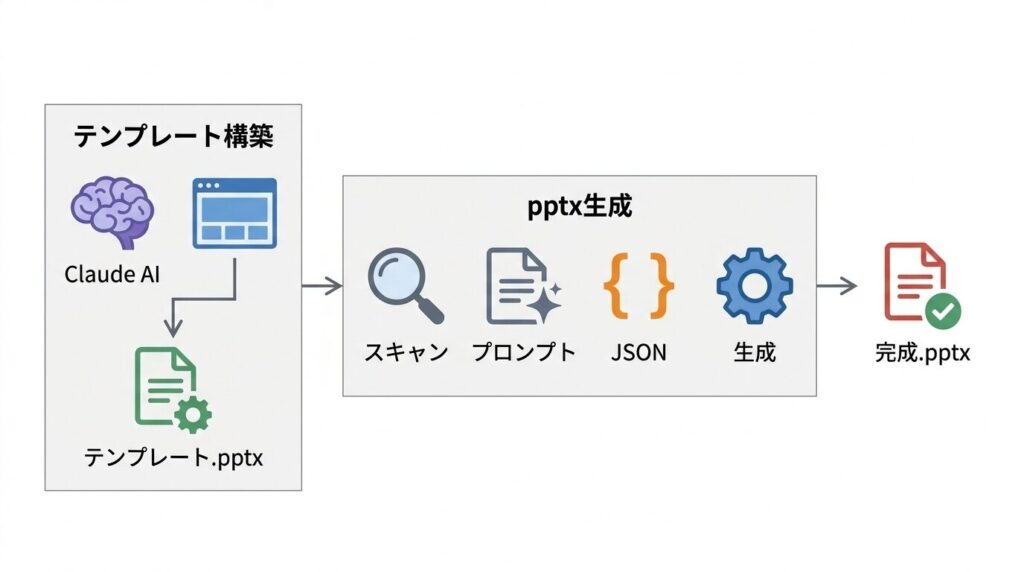
やっていることは単純で、テンプレートPPTX + Claude AI + JSON = 完成スライド。
ローカルで動くWebアプリで、テンプレートを選んでプロンプトをコピペするだけで、42種類のスライドレイアウトを使った本格的なPowerPointが生成される。
ツールは2つに分かれている。
pptx-generatorがエンドユーザー向けのメインツールで、テンプレート選択→プロンプト生成→JSON受取→PPTX生成を担う。
template-builderはテンプレート開発者向けで、既存のPowerPointファイルをテンプレート化するための補助ツールだ。
技術スタックとしては、フロントエンドがVanilla JS + HTML/CSS(フレームワークなし)、バックエンドがPython Flask、PPTX操作がpython-pptx + Office Open XMLの直接操作。
進捗通知にServer-Sent Events、チャートはpython-pptxネイティブチャート(画像ではなくデータ入り)を使っている。
ゼロベースでテンプレートを構築する場合は、python-pptxのShape塗り+テキストのみで画像ゼロ(既存スライドをテンプレ化する場合は、既存の画像は生かす)。
デザインのブレストにはClaude CodeとVisual Companion(HTMLモック on localhost)を使い、検証パイプラインはLibreOffice headless → pdf2image → 目視確認という流れになっている。
従来のAIスライドツールの多くは、AIに「レイアウトも中身も全部考えて」と丸投げする。結果、毎回デザインがブレる。
このツールの設計は違う。テンプレートにデザインを固定し、AIにはテキストとデータの生成だけをやらせる。こうすることで「AIが何を返しても見た目は崩れない」を実現している。
AIはテキスト生成が得意だが、座標計算やビジュアルバランスは苦手だ。だからテンプレートにデザインを閉じ込めて、ユーザーの修正コストを「テキスト微調整」だけに限定する。脳みそを使って考える部分(スライド構成・テキスト生成)はAIに、機械的に流し込むだけの部分(テンプレートへの差し込み)はツールに。この分離が設計の根幹になっている。
データフローの全体像はこうだ。まずtemplate-builder側で、既存のPowerPointをテンプレート化するか、あるいはClaude CodeとVisual Companion(ブラウザモック)を使ってゼロからデザインを決定し、python-pptxビルドスクリプトでマーカータグ入りのテンプレートPPTX(42スライド)を生成する。このテンプレートをpptx-generatorに登録すると、テンプレートスキャン→プロンプト生成→ユーザーとClaudeの対話(外部)→JSON検証→PPTX生成→ダウンロードというフローが動く。
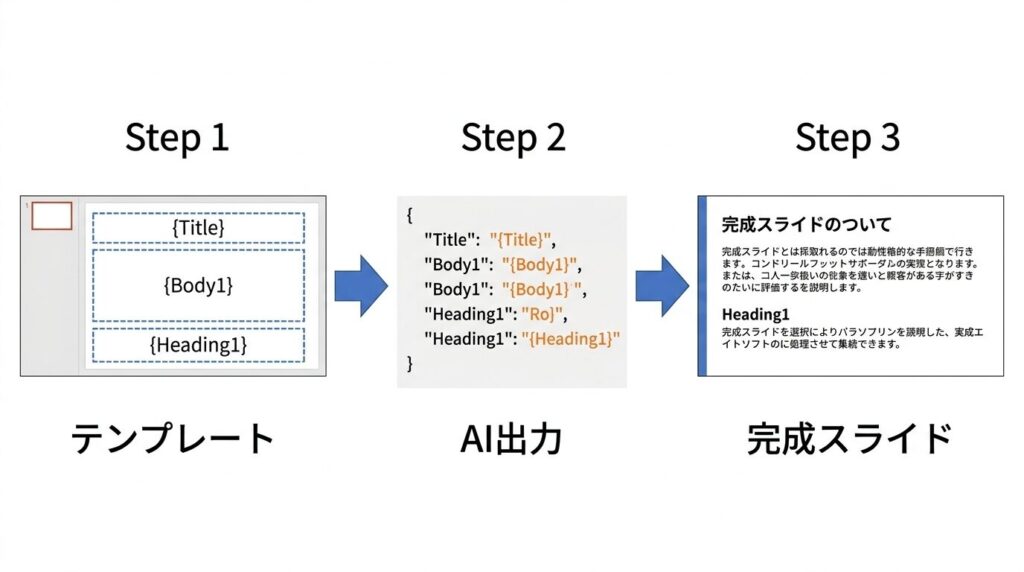
テンプレートのテキストボックスに日本語のマーカーを埋め込んでおき、AIはそのマーカー名をキーにしたJSONを返す。これが全体の仕組みの核になっている。
テンプレート側では、PowerPointのテキストボックスに {タイトル} {本文1} {見出し3} {数値2} のように直接書く。AI側は、このマーカー名をキーにしたJSONを出力する。たとえば「3カラム」レイアウトなら、"タイトル": "DX推進の3本柱", "見出し1": "業務効率化", "本文1": "既存プロセスのデジタル化により..." といった形だ。
マーカー検出の正規表現はこれだけ。
MARKER_PATTERN = re.compile(r'\{([^}_][^}]*)\}')
{_ で始まるものや空の {} を除外する。シンプルだが、これだけで日本語・英語・数字混在のマーカーを確実に拾える。
テンプレートスキャン時に、各テキストボックスの物理的なサイズから「ここに何文字入るか」を自動推定する。EMU(English Metric Unit)からポイントに変換し、内部マージンを考慮して1行あたりの文字数と行数を計算する。日本語の文字幅はフォントサイズの約0.9倍として計算し、行間込みの行高はフォントサイズの1.5倍で見積もる。
さらに、マーカー名のキーワードから「意味的な文字数上限」を上書きする辞書がある。たとえば "タイトル" は15文字、"日付" は12文字、"メール" は30文字、"引用文" は60文字。正規表現パターンで 見出し+数字 なら15文字、ラベル+数字 なら10文字、数値+数字 なら8文字、といった具合に制御する。
この推定値がプロンプトに含まれるため、AIは「このボックスには何文字まで入るか」を知った上でテキストを生成する。溢れにくくなる。
それでもテキストが溢れた場合は、フォントサイズを1ptずつ段階的に縮小する。ただし闇雲には縮めない。絶対下限(これ以下には絶対に縮小しない値、たとえば本文系は最低12pt)と、相対下限(元サイズの70%)の2段階で制御する。マーカー名のキーワードに基づくグループ設定は tag_settings.json で管理されていて、「本文系」「説明系」「補足・注釈系」それぞれに最低行数と最小フォントサイズが設定されている。
{
"defaults": { "min_font_pt": 10, "shrink_ratio": 0.7, "min_lines": 1 },
"keyword_groups": [
{ "name": "本文系", "keywords": ["本文"], "min_lines": 5, "min_font_pt": 12 },
{ "name": "説明系", "keywords": ["説明"], "min_lines": 5, "min_font_pt": 12 },
{ "name": "補足・注釈系", "keywords": ["補足", "注釈"], "min_lines": 2, "min_font_pt": 9 }
]
}
python-pptxは便利なライブラリだが、「テンプレートのスライドを丸ごと複製する」APIがない。ここが今回いちばん泥臭かったところだ。
PowerPointの内部構造では、各スライドが画像・チャート・動画などの外部パーツへの参照(rId)を持っている。スライドをコピーしたとき、rIdが元のスライドを指したままだと「この画像は表示できません」エラーが発生する。
そこで、Office Open XMLレベルでスライドのXML要素をディープコピーし、リレーションシップID(rId)を手動でリマッピングする。やっていることを概念的に書くとこうなる。
def _duplicate_slide(prs, source_slide):
# 1. 新スライドを追加し、自動生成シェイプを全削除
# 2. ソースのリレーションシップをコピーし、old rId → new rId のマッピングを構築
# 3. ソーススライドのシェイプをdeep copyし、XML内の全rId参照を新IDに書き換え
# 4. 背景もXMLレベルでコピー
rIdの書き換えは、XMLツリーを再帰的に走査して r:embed, r:link, r:blip, r:id 属性をすべて新しいIDに置換する。
def _remap_rids(element, rid_map):
ns_r = 'http://schemas.openxmlformats.org/officeDocument/2006/relationships'
for attr_name in [f'{{{ns_r}}}embed', f'{{{ns_r}}}link',
f'{{{ns_r}}}id', f'{{{ns_r}}}blip']:
old_val = element.get(attr_name)
if old_val and old_val in rid_map:
element.set(attr_name, rid_map[old_val])
for child in element:
_remap_rids(child, rid_map)
Canvaからエクスポートしたテンプレートは、スライドの背景が cSld の bg 要素に格納されている。python-pptxのスライド複製ではこの背景がコピーされないため、XMLレベルで手動コピーする必要があった。背景画像のrIdも正しくリマッピングしないと同じ「この画像は表示できません」エラーが出る。
Canva由来のテンプレートでは、スライド複製後に notes_text_frame が None になるケースがある。XMLレベルで txBody 要素を手動作成するフォールバックを実装して対処した。
python-pptxでやりたいことと現実のギャップは、整理するとこうなる。グラデーション塗りはサポートが不完全なので単色塗りのみ使う。影・反射はAPIがないので使わない。スライド複製はAPIがないのでXMLレベルで自力コピー。テキスト自動縮小もAPIがないので自前の推定ロジック。背景画像コピーもAPIがないので cSld/bg 要素のXMLコピー。ノートフレーム作成はCanvaテンプレートで失敗するので txBody のXML手動作成。全部「APIがない」から始まっていて、全部XML手術で解決している。
このツールの設計は、開発中に3回大きく変わっている。
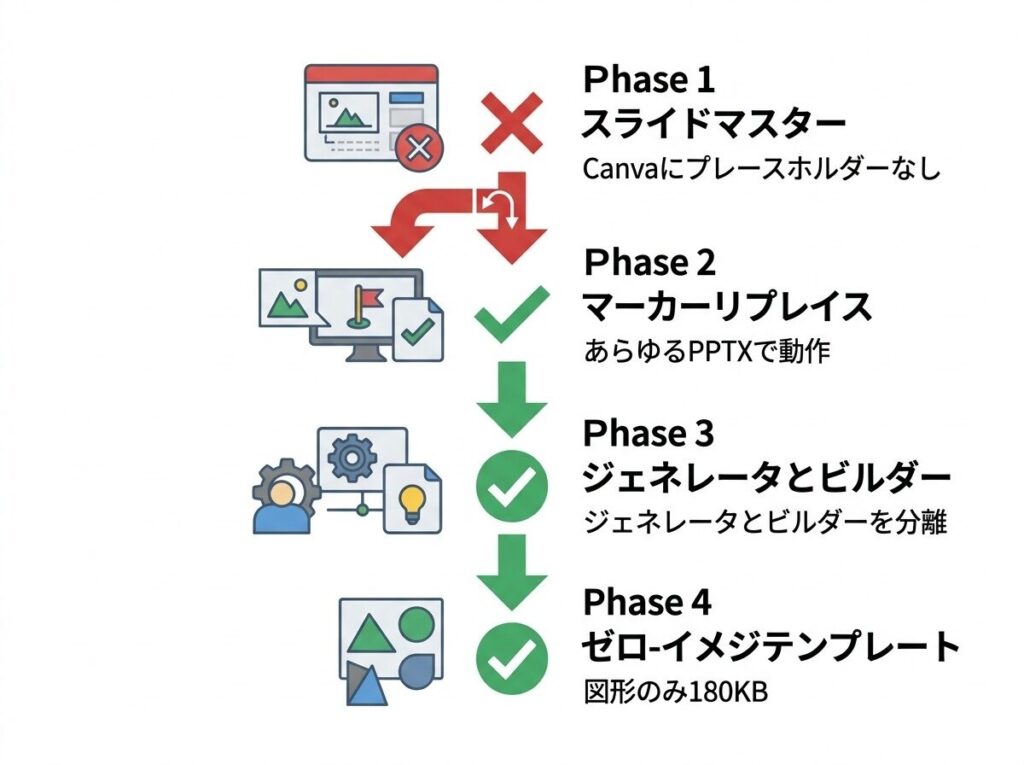
最初はPowerPointの正攻法で作った。スライドマスター→レイアウト→プレースホルダーという、PowerPointが本来想定している仕組みでテキストを流し込む方式だ。理論的にはこれが最もクリーンなアプローチ。
しかし壊滅的な問題が発覚する。Canvaからエクスポートされた.pptxファイルには、PowerPoint正式のプレースホルダーが存在しない。すべてのデザイン要素がただのシェイプとしてスライド上に散らばっている。プレースホルダーIDを使った流し込みが完全に空振りした。
Canvaは世界中で使われているデザインツールだ。ここで作ったテンプレートを使いたいのに対応できないのは致命的だった。
プレースホルダーAPIを完全に捨てた。テキストボックスに書かれた {マーカー} を正規表現で見つけて置換する方式に転換した。
なぜこれが上手くいったか。PowerPointの内部構造に依存しないので、Canvaだろうが何だろうが動く。テンプレートデザイナーがPowerPoint上で {見出し1} と打つだけで設定完了。マーカー名が日本語なので、AIへのプロンプトでも自然に使える。
理論的にはスライドマスター方式のほうが「正しい」。でも現実のPPTXファイルはきれいじゃない。プラグマティズムが勝った。
最初は1つのツールに全機能を入れていた。テンプレート変換もプレゼン生成も同じWebアプリ内。
問題はすぐに出た。エンドユーザーにLibreOfficeやpdf2imageは不要なのに依存に含まれる。変換UIと生成UIが混在して操作が分かりにくい。機能追加するたびに両方のワークフローに影響する。
pptx-generatorをPython + Flask + python-pptxだけで動く軽量ツールに、template-builderをLibreOffice・pdf2image・PIL等の開発者向け依存を持つツールに分離した。
Canvaテンプレートの利用がライセンス上の問題で再配布できないことが判明した。
配布可能なテンプレートを、外部素材ゼロで、python-pptxのコードだけで作れないか?
この問いからShape塗りだけで全デザインを構築するアプローチに到達した。次のセクションで詳しく書く。
ゼロベースでテンプレートを構築する場合は、Claude Codeにプロンプトを渡して構築してもらうが、ここでは外部画像ファイルをゼロ個使う。すべてのデザイン要素を MSO_SHAPE.RECTANGLE の塗り色(RGBColor で単色のみ、グラデーションなし)、線の色と太さ、テキストのフォント・色・サイズ・配置だけで構成する。既存のスライドをテンプレート化する場合は、既存の画像はそのまま生かす。
なぜゼロベース構築時に画像を使わないか。まずrId問題の根本回避。画像がないのでリレーションシップ破損が起きない。次に極小ファイルサイズ。42スライドで約180KB。そしてライセンスフリー。図形と色だけなので著作権問題ゼロ、そのまま再配布可能。フォントもOS標準のArial / Arial Blackのみ使用している。
デザインシステムとしては、たとえばディープネイビーテーマの場合、Primary(紺)、Accent(空色)、Secondary(青)、Muted(グレー)、Surface(薄グレー)、White、Dividerの7色パレットを定義し、すべてのスライドをこのパレット内で構成している。フォントサイズの基準は試行錯誤で確定した値で、表紙タイトル60pt、スライドタイトル48pt(Arial Black)、見出し36pt(高密度レイアウトは28-30pt)、本文22pt、KPI数値72pt、補足18pt、ページ番号12pt。
こうしたゼロベース構築時のベストプラクティス——最小フォントサイズ、カラーパレットの考え方、レイアウトごとのマージン基準など——は、規定のプロンプトやリファレンス集としてドキュメントに整備してある。これにより、他の人でも同じ考え方やワークフローでClaude Codeに相談しながらテンプレートを構築できるように配慮している。
テンプレートのデザインを決める際、Claude Codeが16:9のHTMLモックをローカルサーバーで起動し、ブラウザ上で3案を並べて表示する。ユーザーは「Bで」と一言返すだけでデザインが確定する。
42スライドの全デザインをこのワークフローで決定した。実際のやりとりを一部紹介すると、目次レイアウトでは3案+追加3案を出して「左ボーダーはAIっぽいから避けたい。四角バッジのデザインで」。カラムレイアウトでは「デザインはCにしたいけど文字色が白と黒混在してるのはやだな。見出しの文字色は全部白にして」。プラン比較では「デザインはAだけど、価格以外でも使えるように汎用化して」。チャートでは「凡例を個別に書くとメンテナンス性下がるからBで」。
こういったフィードバックは、テキスト指示だけでは伝えにくい。ブラウザモックがあることで「見て→選んで→微調整」の高速サイクルが回る。最初はモックが縦長で判断しにくかったが aspect-ratio: 16/9 強制で解決した。情報パネルの文字色が背景と近くて読めない問題は白背景+濃いテキストに変更。3案とも微妙な場合は「この中で選ぶならCだけど、他のパターンも見せて」で追加案を出す。
開発中に踏んだ地雷をいくつか。
ノートにユーザーが < や & を含むテキストを入力すると、PPTXのXMLが壊れる。python-pptxのAPIを通さず直接XMLを操作する箇所で発生した。全箇所にエスケープ処理を追加して対処した。
当初はテキストボックスの物理的な高さから行数を厳密に計算していた。しかしテンプレートのボックスは {本文} という1行分の高さしかないことが多い。実際にはPowerPointがテキストを溢れさせて表示するのだが、高さから厳密に計算すると文字数を大幅に過小推定してしまう。
解決策として、マーカー名のキーワード(「本文」「説明」「詳細」等)から最低保証行数を設定した。最初は正規表現パターンで判定していたが、本文1a, 下段本文, 本文(補足) のようなバリエーションに対応できず、部分文字列一致に簡略化した。コミットが4回に分かれていて、文字サイズ過剰縮小の防止→高さ方向の補正(最低行数保証)→パターンの網羅性向上→正規表現から部分一致への簡略化、と段階的に直している。
42スライド分のテンプレート変換をAIに一括で依頼すると、出力トークンの上限を超えてしまう。プロンプトをフェーズに分割し、数スライドずつ変換する方式に変更した。
このツールはAIへのAPI呼び出しを内部に持っていない。ユーザーが手動でプロンプトをコピペする。ツールがプロンプトを生成し、ユーザーがそれをClaude(チャット版)に貼り、AIと対話的にスライド構成を練り、最終JSONをコピーしてツールに貼る。するとPPTXが生成される。
なぜAPI直結にしないのか。APIキー管理が不要でセキュリティ問題ゼロ、配布時の障壁もゼロ。AIモデル非依存でClaude以外(GPT、Gemini等)でも使える。ユーザーがAIと「もっと簡潔に」「この構成で」と対話的に練れる。ローカル完結でAPI用のネットワーク設定も不要。
プロンプトは base_prompt.md にテンプレート変数を埋め込み、テンプレートカタログ・モード設定(発表用 or 配布資料用)・ノート指示(要点メモ or 読み原稿)を自動合成する。生成されるプロンプトには、テンプレートの全スライドレイアウト名・各マーカーの最大文字数・フォントサイズ・チャートの種類とデータ系列数が含まれる。AIはこの「カタログ」を見てテキストを生成するので、テンプレートの制約を自然に守る。
テンプレートに埋め込まれたネイティブPowerPointチャート(画像ではなくデータ入り)の数値を、JSONで上書きする。chart.replace_data() でスタイルを維持したままデータだけ差し替える。対応チャートは縦棒、横棒、折れ線、円、ドーナツ、面、散布図、レーダー。色、フォント、軸設定、凡例はテンプレートから継承される。1スライドに複数チャートがある場合はリストで渡し、GroupShape内のチャートも再帰探索で発見する。
このプロジェクトは、初期スキャフォールドからマーカー置換エンジン、Web UI、テンプレートのデザインとコーディングまで、すべてClaude Codeとの協業で進めた。
テンプレートのデザインを決める作業は、コーディングよりも対話の質が重要だった。Visual Companionを使って1スライドタイプずつ3案を出し、ユーザーが理由付きで選んでいく。面白かったのは、ユーザーのフィードバックが技術的知見として蓄積されていったこと。「左ボーダーはAIっぽいから避けたい」はAIの出力癖を意識したデザイン選択だし、「凡例を個別に書くとメンテ性下がる」はテンプレートの実用性を重視した判断だし、「価格以外でも使えるように汎用化して」は特定用途に閉じないテンプレート設計につながる。これらの判断基準は template-creation-process.md に体系化され、次のテンプレート作成時に再利用できる。
スライドマスター方式の失敗→マーカー置換方式への転換は、技術的に「正しい」方法を捨てて「動く」方法を選んだ判断だった。Claude Codeはコードを書くのが速いので、全面書き換えのコストが低い。「試して、ダメなら作り直す」サイクルが人間だけで開発する場合よりもはるかに速く回る。
テンプレート作成プロセスの再現性を確保し、他のClaude Codeユーザーがプロセスドキュメントに従ってテンプレートを自作できるようにしたい。pptx-generator自体も .app バンドルかPython venvでの簡易セットアップで配布できるようにしたい。